
Overview
What will be the next revolutionary paradigm in artificial intelligence and machine learning (AI/ML)? I believe the answer lies in reinforcement learning (RL), a powerful yet straightforward approach to training decision-making abilities for machines.
Humans are constantly making decisions. In fact, adults are estimated to make about 35,000 remotely conscious decisions each day [1]. Consider how you choose what to eat each day; if you're like me, your meal selections are far from predictable, often chosen semi-randomly to promote a balanced diet. This is but one example of how human decision-making often isn't bound by patterns but rather guided by goal-based policies.
Deep learning, which underpins most popular ML architectures like Large Language Models (LLMs), excels at pattern recognition. In contrast, reinforcement learning is designed to tackle decision-making policies. Deep reinforcement learning fuses these two paradigms and has delivered remarkable achievements in tasks ranging from video game playing to autonomous control. However, deep RL faces challenges related to scalability and applicability. Many deep RL applications necessitate weeks of training on high-performance clusters and often require specialized design for specific tasks, limiting their versatility.
Despite these challenges, my aim was to evaluate the potential of deep reinforcement learning to master Risk, a game I love. This article outlines the methodology used to create a proof-of-concept RL agent, presents my findings from initial experiments, and explores the next steps for this project and the reinforcement learning field as a whole.
Problem
Can a reinforcement learning agent outperform human players in the game of Risk?
Risk’s extraordinary game complexity makes this difficult to evaluate. To provide context, game complexity can be assessed using two key metrics: the state-space (the number of possible game states) and the average branching factor (the number of game states accessible from a decision point). Risk boasts a vast state-space of approximately 10^47 and an average branching factor ranging from 10^6 to 10^85, with no theoretical limits [2]. In contrast, chess has a state-space of about 10^44 and an average branching factor of 35 [3].
Given the immense complexity of Risk, my objective shifted to determining if a reinforcement learning agent could merely show performance improvement in a Risk-like simplified scenario at a small scale. If successful, this would offer hope that with increased scale, an RL agent could eventually challenge and surpass the ability of human players.
Methodology
I developed a deep reinforcement learning algorithm specialized for a simplified, single-agent Risk scenario. The design considerations, covering the environment, action space, reward model, and parameters, are detailed below:
- Environment
- The Risk board was simplified as a two-dimensional 4x4 grid array, with each cell representing a territory and its value representing the troop count.
- The board's initial state, which determines territory ownership, was set randomly at the beginning of each run.
- The four quadrants of the 4x4 array (2x2 cells each) represented continents, as capturing all the cells in those quadrants resulted in additional bonus troops to place.
- Actions
- In a typical Risk turn, three primary actions include placing troops, attacking, and fortifying. For simplicity, the three actions were combined to a single one per step: the RL agent was only able to choose an 'action vector' (from -> to). Refer to the figure below for examples. Troop placement and fortification occured automatically.
- Attacks were limited to neighboring squares, except for attacks across borders which were technically allowed but resulted no change to the environment.
- The attacking sequence was modeled as iterative and random dice rolls, similar to Risk, and played out to completion.
- Reward Model
- Basic reward shaping was applied to provide small intermediate rewards to the model after the initial terminal-based sparse reward model resulted in a lack of convergence. The reward model was as follows:
- +0.5 for capturing a square
- +100 for winning
- -0.5 for all other turns
- Basic reward shaping was applied to provide small intermediate rewards to the model after the initial terminal-based sparse reward model resulted in a lack of convergence. The reward model was as follows:
- Architecture and parameters
- The expected SARSA method was used, akin to the widely used Q-learning approach, which updates state-action pair values based on the expected next state-action pair value estimates.
- The action-value function was modeled as a two-layer feedforward neural network, with the input being the board state, hidden layers consisting of ReLu functions with 32 x 16 hidden units each, and the output providing action values.
- For exploration, a softmax policy was implemented with a tau value of 0.1.
- The learning rate parameter was set at 0.95.
- An experience replay technique was employed.
Shown below is an illustrative example of the state space and possible actions, based on the visualization function used to generate the animation included later in the Conclusions section.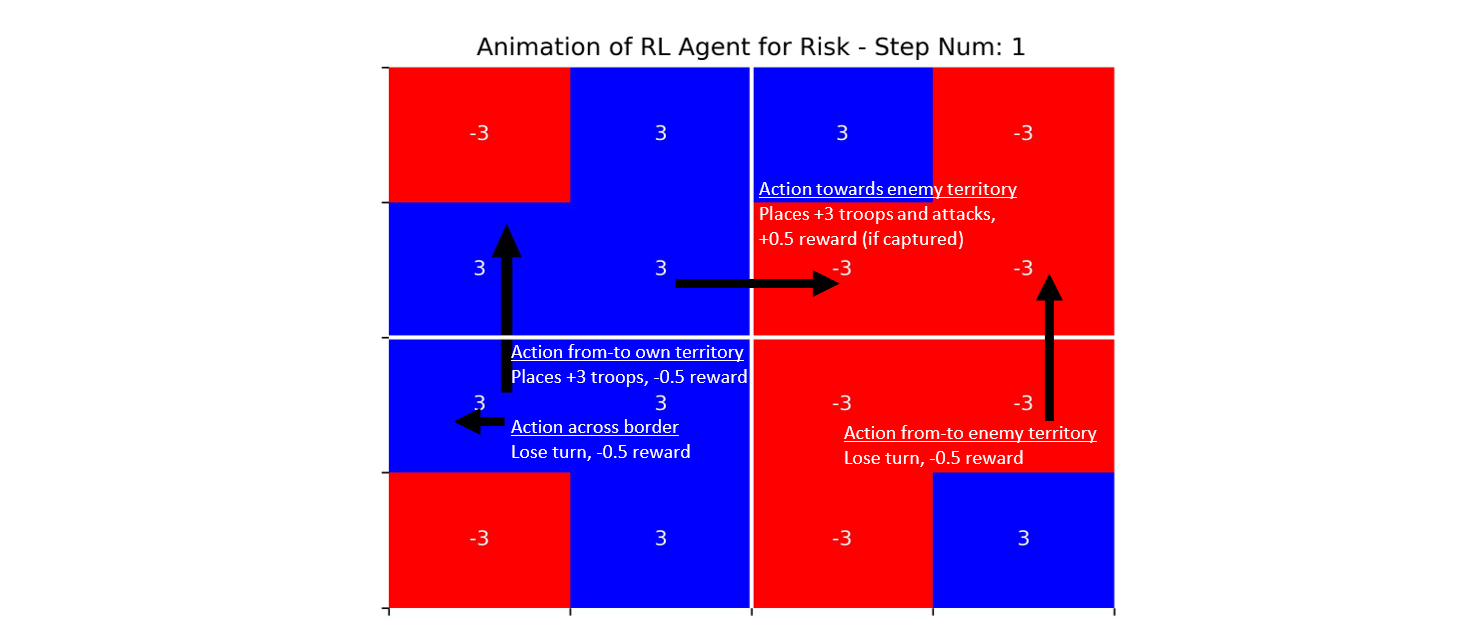
Figure: Annotated visualization of the game state and actions. Blue cells represent the territories of the RL agent. Red cells (which also have negative values) represent the territories of the neutral player. The solid white lines represent the quadrant ‘continents’ for which capture yields extra bonus troops. Note an agent is technically permitted to attack in the direction of the edges of the board, however those attacks yield no change to the state.
The program code can be accessed in this public repository within the POC_v1 directory. The code’s structure includes:
- `main.ipynb`: A Jupyter notebook with functions to run the experiment and control the agent. Additional Jupyter notebooks for running various tests are also included.
- `rl_glue.py`: The class that orchestrates (‘glues’) the necessary functions and classes for an experimental run.
- `environment.py` and `agent.py`: Containing abstract classes for use by `rl_glue.py`.
- `agent_funcs.py`: Containing the neural network functions.
- `environment_alphagear.py`: Containing functions representing the environment and reward model.
- `dynamics.py`: Containing functions dictating how the environment changes in response to an action.
The results mentioned in the conclusion are derived from the experiment in `main-plot_animate-test.ipynb`, utilizing these hyperparameters:
- Number of runs: 1
- Number of episodes = 3000
- Maximum number of steps per episode = 400
These experiments were run on my PC with an Intel Core i7-8550U CPU (with a measly 2.00 GHz max clock speed) and 8GB of RAM. It took 27.7 hours to conduct the 3000-episode training experiment.
Conclusions
The experiment results indicated that the RL agent had the potential to learn. However, they did not suggest that scaling alone would lead to super-human performance. Simply put, the agent learned just enough to surpass random decision-making. To provide context, an optimally trained agent could likely solve the 4x4 board in 20 steps or fewer. After 3000 training episodes, the agent managed to solve the board in 166 steps. While this may not appear as a significant accomplishment, it's worth noting that random agents often require over 400 steps.
The plot below shows the learning curve of the agent. There's a noticeable inflection point around the 500-episode mark, after which the agent consistently reaches the terminal state, earning the +100 reward.
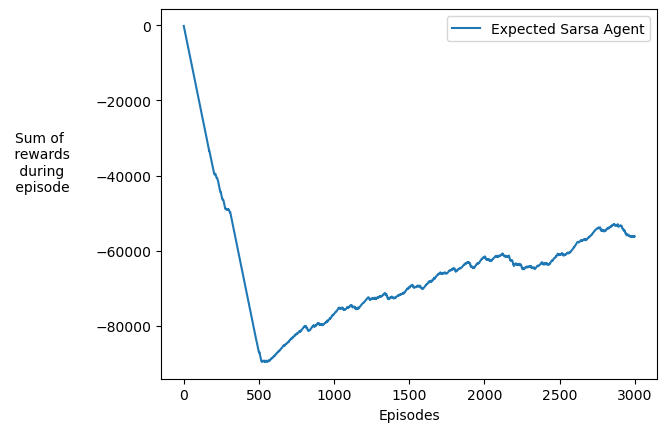
Figure: A plot of the total cumulative rewards as a function of the number of training episodes of the Risk agent.
The animation below showcases the agent's performance in episode 3000. It's evident that the agent does not exhibit human-level intelligence. It struggles to consistently attack enemy territories and fails to grasp the concept of capturing continents first. Nevertheless, one could argue that the agent has developed some understanding of the board's edges and a rudimentary concept of friendly and enemy territories, as it frequently chooses attack vectors from its own territories.
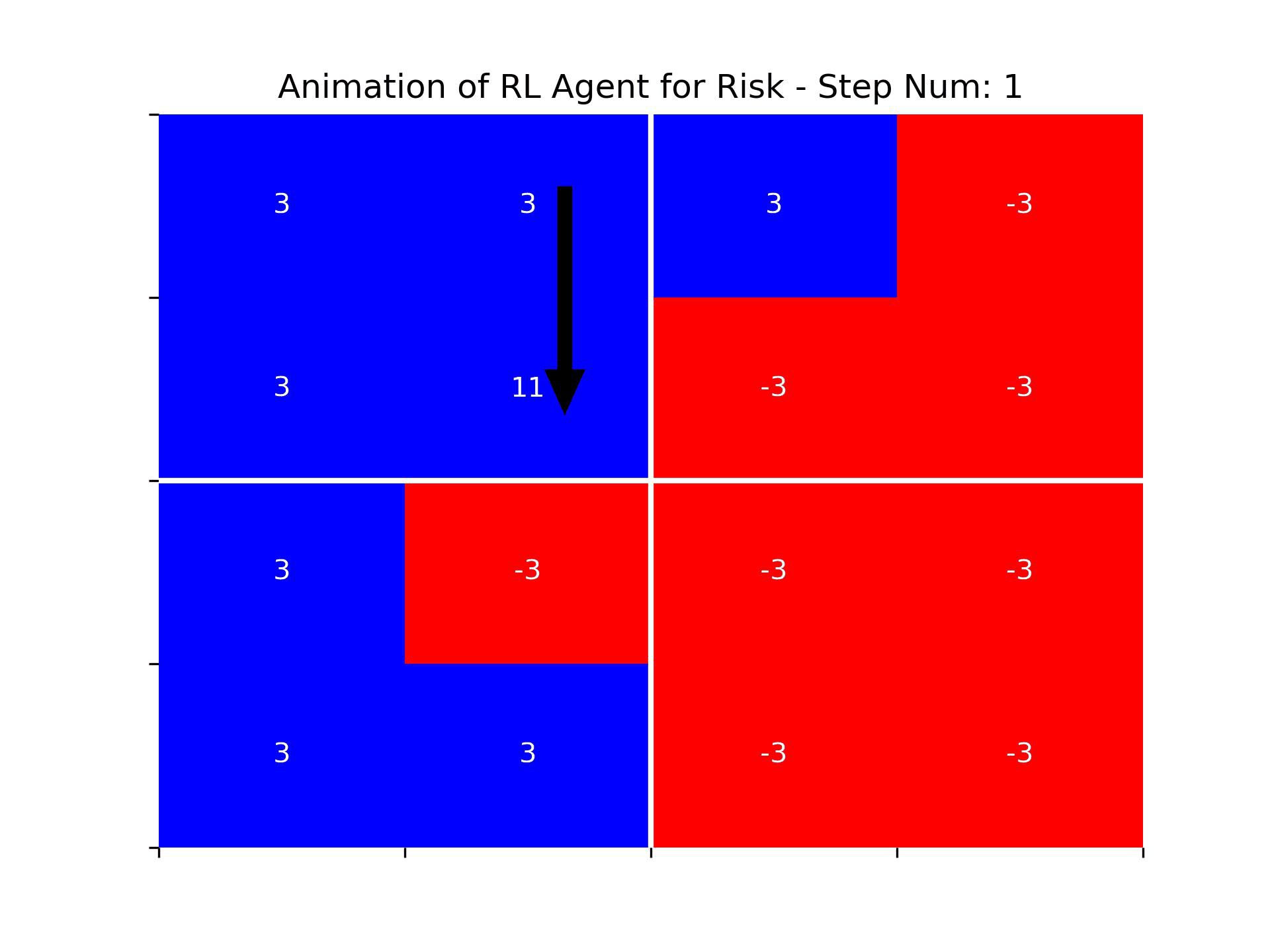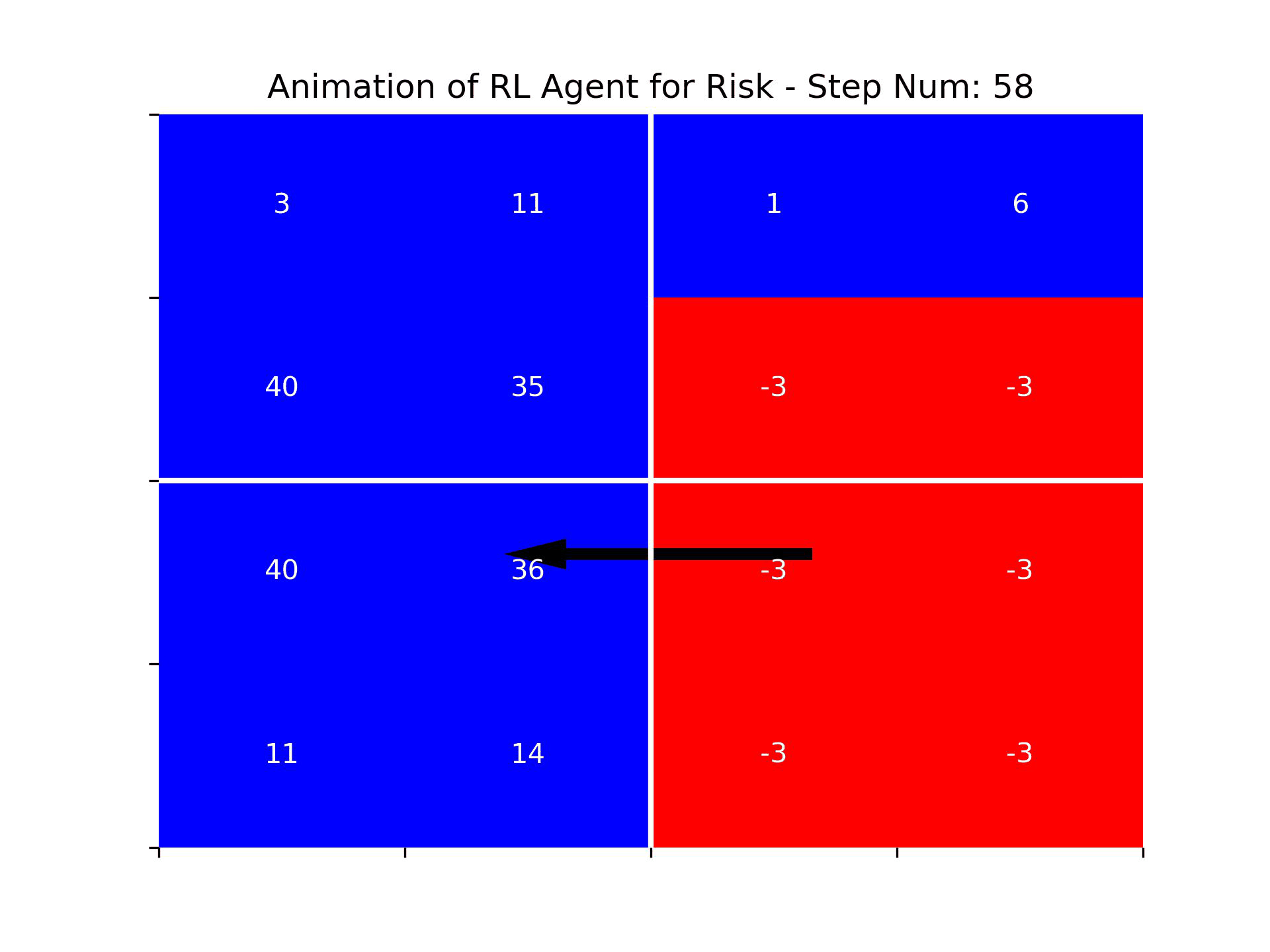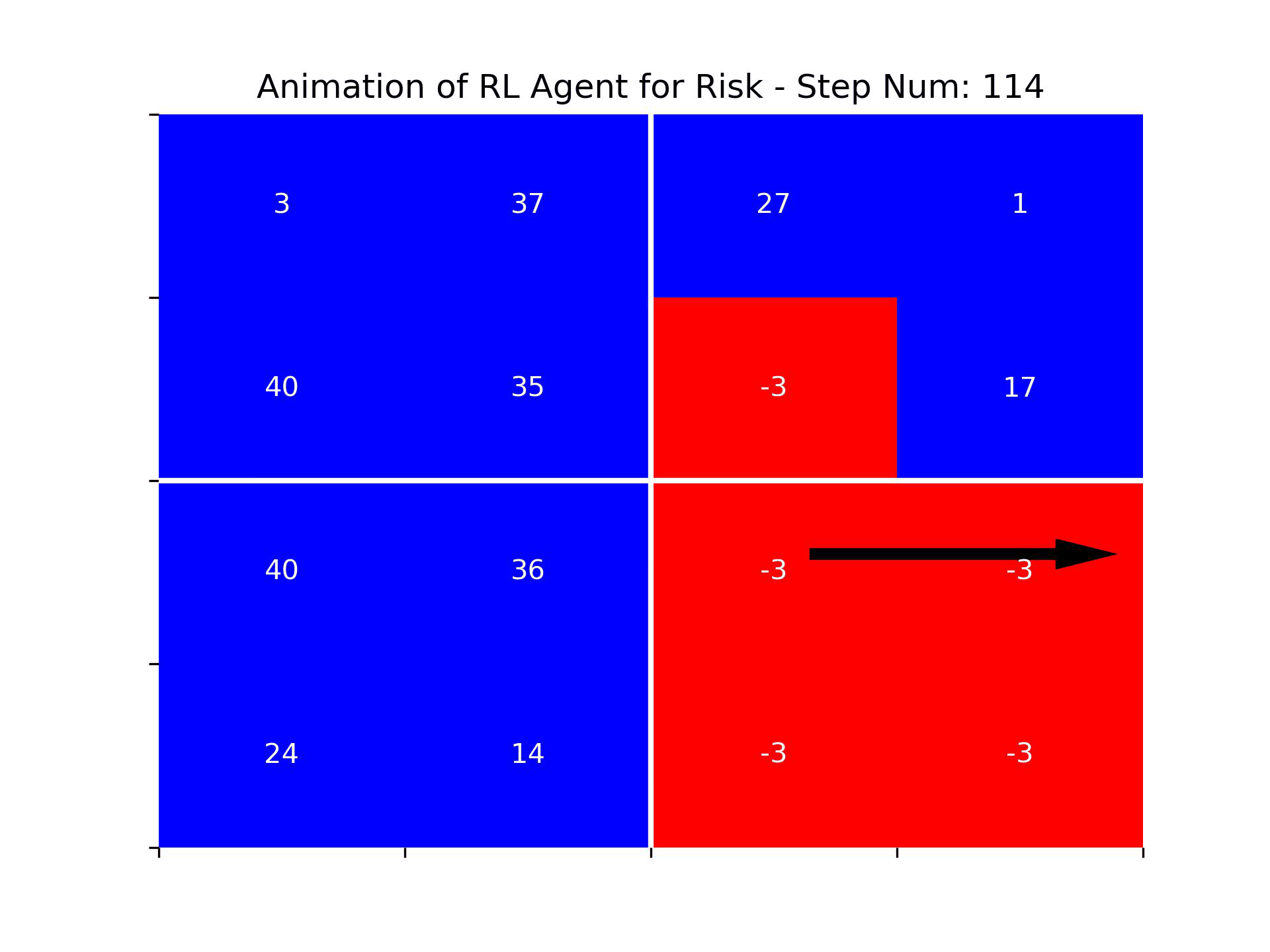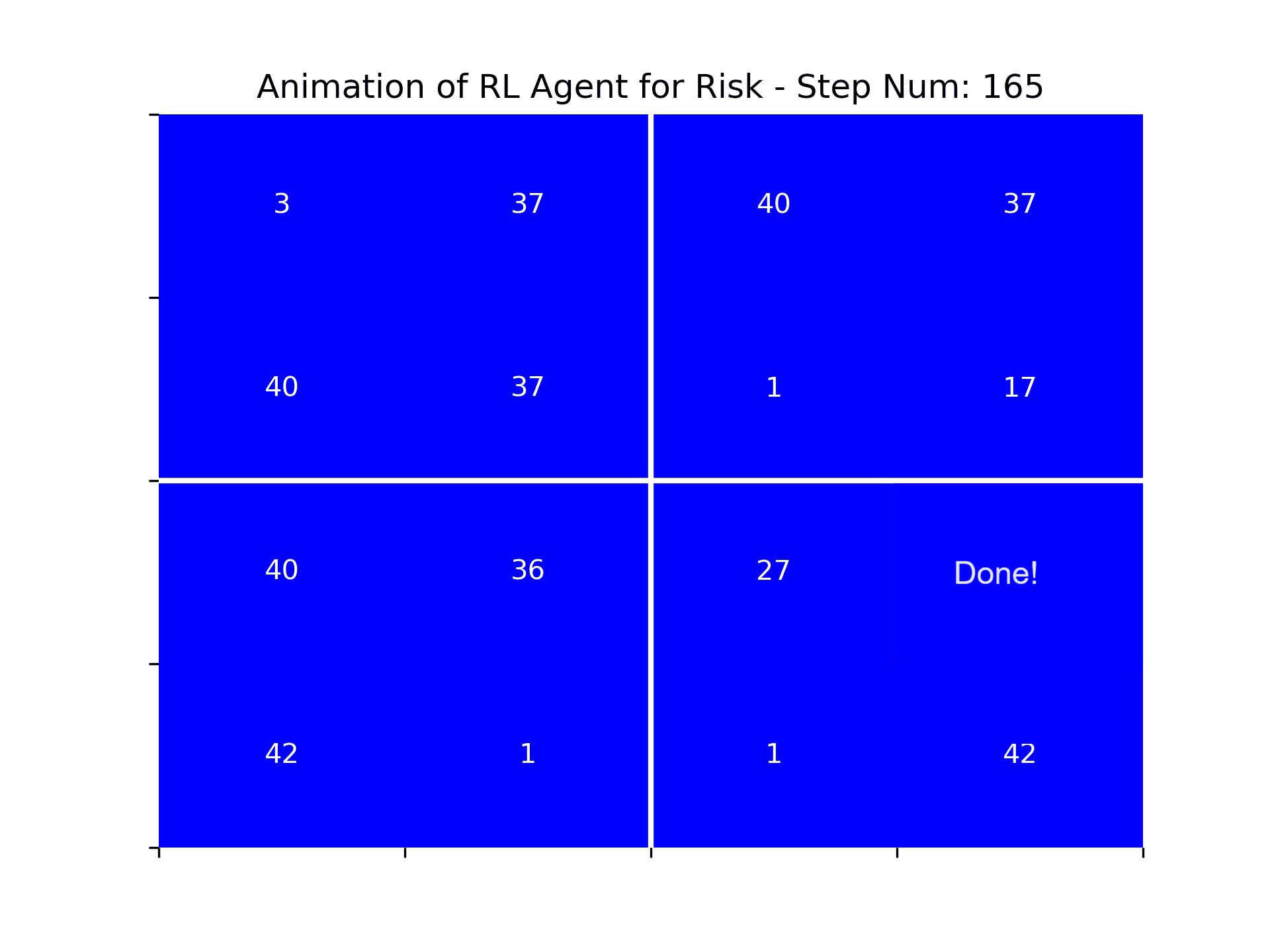 Figure: An animation showing the actions of the RL agent in episode 3000 of training. The agent seems to demonstrate strong performance only after step 150, once there were few remaining territories to be captured. It is possible that the network hasn’t learned how to act well at the beginning of the game because backpropagation of the update from the terminal state hadn’t fully adjusted the action values of early game states.
Figure: An animation showing the actions of the RL agent in episode 3000 of training. The agent seems to demonstrate strong performance only after step 150, once there were few remaining territories to be captured. It is possible that the network hasn’t learned how to act well at the beginning of the game because backpropagation of the update from the terminal state hadn’t fully adjusted the action values of early game states.
In summary, the Risk agent displayed the ability to learn and make slight improvements in decision-making. However, these results do not suggest that a turning point in performance is imminent with increased training time.
Next Steps
Scaling this proof of concept into a practical system requires optimization, additional features, and computational resources.
First, optimization is needed to resolve the complexity of Risk and make the algorithm more sample efficient. Key considerations include:
- Converting the algorithm to leverage existing deep learning libraries such as KerasRL.
- Initializing the output of the state-action neural network to “mask” pre-determined illegal actions (for instance, attacking from a territory not owned).
- Reducing exploration as a function of the agent’s learning. Potential methods include setting the tau parameter to the inverse of the variance of the action-value function or as a function of the number of steps taken in the last episode(s) [4].
- Pretraining the algorithm on human gameplay data (scraped from sites such as Wargear.net).
Second, additional features must be added to the program to better represent Risk, including:
- Converting the 2D state array, which is useful for visualization, to 1D vectors in order to accommodate territories with more than four neighboring territories, as well as additional agents.
- Splitting action selection into the three stages of a Risk turn: placing troops, attacking and fortifying.
- Adding additional agents. This will be the last feature added as the exploration space of deep multi-agent RL scales exponentially with the number of agents [5]. Furthermore, the states would need to become “non-deterministic”, for instance by modeling beliefs about the players with probability distributions of the state.
Last, access to a substantial amount of compute will be necessary to test and refine the model. Exploring cloud-based GPU VMs (I am accepting donations) and collaborating with research institutions are potential avenues.
Discussion
Reinforcement learning currently finds most of its applications in modeling games due to their well-defined action-space and reward models. The hope is that the techniques developed for games can eventually be extended to more general applications. In this sense, reinforcement learning is in a stage analogous to deep learning in the late 80s when neural networks were primarily used for basic applications like alphabet recognition [6]. By building on those techniques, thirty years later deep learning achieved mass adoption through large language models (LLMs).
To become a disruptive technology, reinforcement learning needs to progress on each facet of Roger’s five factors framework. First, the relative advantage of RL over deep learning and standard control system algorithms must be unlocked through greater scalability and efficiency. Similar to how the transformer architecture catapulted deep learning, a novel architecture might be needed for RL. In fact, ongoing research is exploring the integration of NLP techniques for RL, due to their capabilities for attending to long-range dependencies in sequences of data [7]. Second, the compatibility of RL could be improved by abstracting task-specific definitions of actions, states, and rewards, similar to how tokenizers and embeddings enabled LLMs to be trained on a large corpus of web data. Third, the complexity of RL could be reduced through more robust libraries and frameworks. Last, the trialability and observability of RL could be provided via tools to visually build simulations of environments and observe the actions of agents. One idea is to lean into the game origins of RL by providing a low-code console to create simulations, such as that in Sims or Roller Coaster Tycoon.
In conclusion, this project highlighted the formidable challenges as well as the remarkable potential of reinforcement learning. I believe that these challenges will be overcome and when that occurs, reinforcement learning will emerge as the foundation of the next ground-breaking AI technology.
Acknowledgements
I'd like to express gratitude to Alec Meade, who contributed to the algorithmic design considerations. Special thanks to Erik Blomqvist, with whom Alec and I discussed his prior research on creating an RL agent for Risk. Erik's work was more advanced, yet despite extensive self-play and a large research compute cluster, “[its] network failed to learn a good scalar state evaluation function”. Erik's suggestions helped simplify the algorithm for this proof-of-concept.
References
[1] https://www.pbsnc.org/blogs/science/how-many-decisions-do-we-make-in-one-day
[2] https://kth.diva-portal.org/smash/get/diva2:1514096/FULLTEXT01.pdf
[3] https://en.wikipedia.org/wiki/Game_complexity
[4] https://arxiv.org/pdf/2205.00824.pdf
[6] https://en.wikipedia.org/wiki/History_of_artificial_neural_networks

{kind=link}